
How to Extract Data from PDF A Practical Guide
Getting data out of a PDF can be as straightforward as a quick copy-paste or as complex as deploying an AI to process thousands of files. The right path really hinges on one crucial detail: whether you're dealing with a text-based digital PDF or a scanned image. Each type demands its own set of tools and a completely different game plan.
Why Is Getting Data Out of PDFs Such a Headache?
Think of a PDF as the digital version of a printed page. It's designed to lock in a document's layout and look the same no matter where you open it, which is great for sharing. But that strength is also its biggest flaw when you need to actually use the data inside.
All that valuable information—invoice numbers, customer details, financial figures—is trapped in a static format. It’s not meant to be easily pulled into a spreadsheet or database. For businesses, this creates a major bottleneck. Manually retyping data from hundreds of invoices isn't just mind-numbing; it's slow, costly, and a recipe for human error.
Converting that static information into something structured and useful, like a CSV or Excel file, is the real goal. It allows you to:
- Analyze with ease: Sort, filter, and find trends in your data.
- Automate workflows: Push information directly into your accounting software or CRM.
- Slash errors: Get rid of the typos and mistakes that creep in with manual entry.
- Save serious time: Free up your team from hours of repetitive copy-and-paste work.
Digital vs. Scanned PDFs: The Critical Difference
Before you even think about which tool to use, you have to figure out what kind of PDF you have. This single step will dictate your entire approach. This decision tree lays out the two main paths you can take.
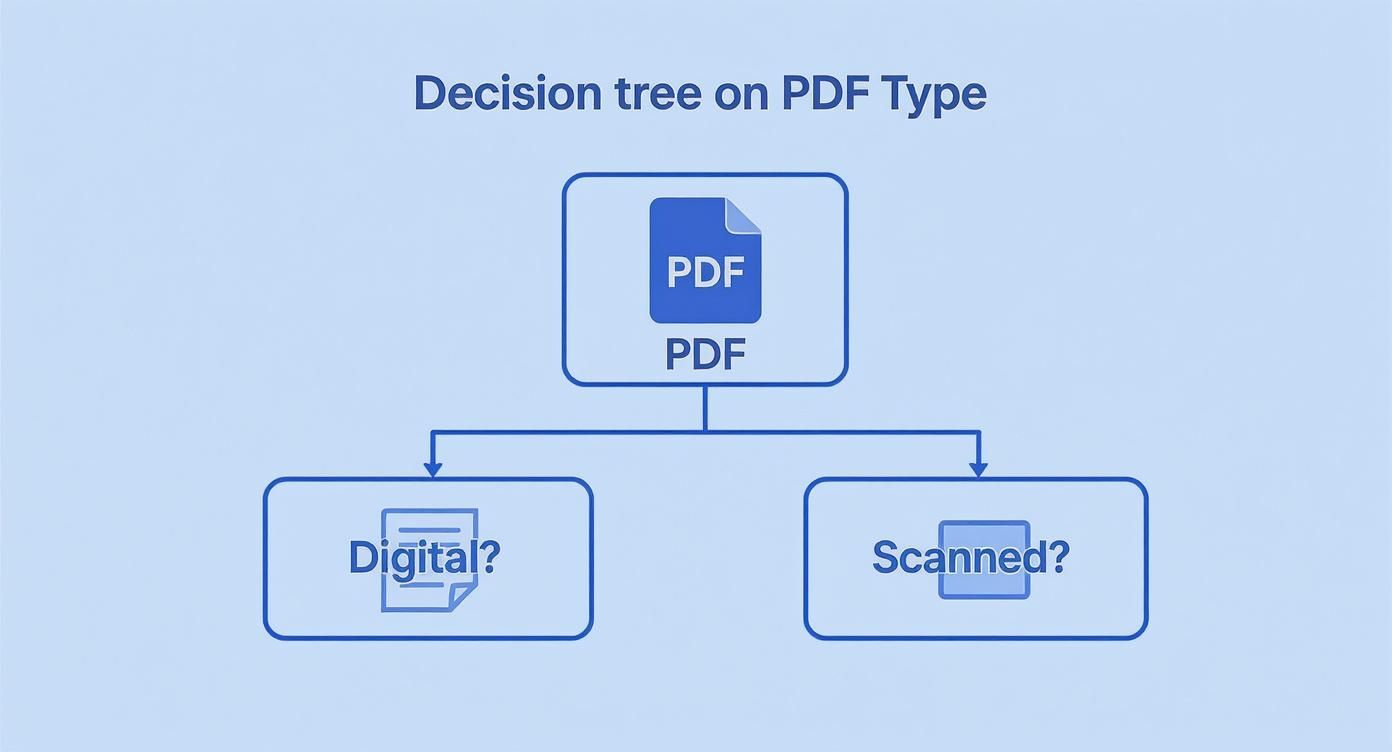
As you can see, the first question is always whether the PDF contains selectable text or is just a flat image. A scanned document, for example, is essentially a photograph of a page. To make it machine-readable, you first need to run it through a technology called OCR. To get a better handle on this foundational tech, check out our guide on what is Optical Character Recognition.
The real challenge isn't just pulling text out of a PDF; it's understanding the structure of that text. An AI-powered tool can differentiate between a "shipping address" and a "billing address" even if they look similar, whereas a simple script cannot.
The need for smart solutions is growing fast. The market for PDF data extraction is on track to hit $2.0 billion by 2025, expanding at a compound annual rate of 13.6%. This trend, highlighted in market analysis from platforms like Parseur.com, shows just how vital automated document processing has become for businesses trying to get more efficient.
Comparing PDF Data Extraction Methods
To give you a clearer picture, here's a quick breakdown of the three main approaches we'll explore. Each has its place, depending on your resources, timeline, and the scale of your project.
| Method | Best For | Technical Skill Required | Scalability |
|---|---|---|---|
| Manual | One-off documents or very small batches with simple layouts. | None | Very Low |
| Open-Source | Developers comfortable with coding who need custom solutions for consistent layouts. | High (Python, etc.) | Medium to High |
| AI Platforms | Businesses needing to process large volumes of varied and complex documents accurately. | Low to None | Very High |
As the table shows, there's no single "best" method—it's all about what works for your specific situation. In this guide, we'll walk through all three: the manual grind, coding with open-source libraries, and tapping into the power of specialized AI platforms.
The Manual Approach for Quick and Simple Tasks
Let's start with the basics. Sometimes, the most effective tool is the one you already know how to use. For quick, simple data extraction jobs, nothing beats the classic copy-and-paste.
If you just need to grab a client's address from a single PDF contract or pull a few key numbers from a one-page report, this is your method. It's direct, requires no special software, and gets the job done in seconds. You just open the PDF, highlight the text, and paste it where you need it—a spreadsheet, a database, or even just an email. It’s fast, free, and familiar.
Of course, anyone who’s done this knows it's often a bit of a fight. PDFs can be stubborn, especially when you’re trying to pull out nicely structured data like a table.
Making Manual Extraction Less Painful
While copy-and-paste has its limits, you aren't completely helpless. A few simple tricks can make the manual process much smoother. The most common headache? Text from multiple columns getting squashed into a single, jumbled block when you paste it.
Here’s how to get around that:
- Use the Column Select Tool: Most people don't know this, but in a program like Adobe Acrobat Reader, holding down the Alt key (or Option key on a Mac) while you drag your mouse lets you select a neat, vertical block of text. This is a game-changer for preserving column structure.
- Try Paste Special: When you're moving data into a spreadsheet, don't just hit Ctrl+V. Use the "Paste Special" option and choose "Text." This little step strips out all the weird formatting that PDFs try to bring along for the ride.
These small adjustments can save you a surprising amount of time on cleanup.
The real test for manual extraction comes when you try to copy a table. More often than not, rows and columns collapse, turning a neatly organized table into a chaotic mess that requires tedious manual reformatting.
This is the hard limit of the manual approach. If you find yourself trying to piece together a multi-page table that refuses to paste correctly into Excel, it's a clear sign you’ve hit the ceiling. The time you spend fixing all the formatting errors quickly eats up any initial convenience.
For a deeper dive into organizing data once it's in a spreadsheet, our guide on data parsing in Excel offers some helpful tips.
Ultimately, manual extraction is a fantastic tool for the right job—small, infrequent tasks. But the moment you start dealing with complex layouts or find yourself doing the same copy-paste routine over and over, it's time to look at more powerful, automated solutions.
Rolling Up Your Sleeves with Python Libraries
If you're comfortable with a bit of code and need more power than manual copy-pasting can offer, Python is your best bet. Open-source libraries give you the ultimate control to build a custom extraction workflow, which is perfect for developers or data analysts dealing with a steady stream of PDFs that all follow the same format.
You're essentially building your own little data extraction engine.
For this kind of work, two libraries are the go-to tools in the community: PyPDF2 for pulling out general text and tabula-py for wrestling with tables. PyPDF2 is great for reading a PDF page by page, grabbing all the raw text, and then letting you sift through it with regular expressions to find what you need. It’s a solid first step for text-based PDFs.
But let's be honest, tables are where the real headaches begin. That’s where tabula-py comes in. It’s built specifically to recognize table structures in a PDF and convert them straight into a Pandas DataFrame. If you work with data in Python, you know a DataFrame is exactly what you want.
Getting Started with PyPDF2
As you can see from its official package page, PyPDF2 is a popular, well-maintained library. You're not relying on some abandoned project.
The constant activity here is a good sign—it means the library is reliable and keeps up with changes. Its functions for opening, reading, and looping through PDF pages are straightforward enough that you can get started without too much of a learning curve.
Let's say you're trying to grab an invoice number. A simple script could pop open the PDF, extract the text from each page, and then hunt for the line that says "Invoice Number." Easy enough.
A Word of Caution from Experience: Custom scripts are powerful but incredibly brittle. I've seen them break countless times because a company decided to slightly tweak their invoice template. If you go this route, be prepared for regular maintenance to keep your extractor from failing silently.
The need for more resilient solutions is why the data extraction software market is booming. It's valued at USD 2.5 billion in 2025 and is expected to rocket to USD 9.8 billion by 2034, growing at a 16.4% CAGR. This isn't just about simple text scraping anymore; it's about intelligent, adaptable technology. You can dig deeper into the data extraction software market and its projected growth to see where things are headed.
A Look at a Real-World Script
Talk is cheap, so let's look at some code. Imagine we have a typical invoice and need to pull out two key pieces of information: the invoice number and the total amount due.
Here’s a small Python script that uses both PyPDF2 for the text and tabula-py for the table data.
import PyPDF2 import tabula import re
File path to your PDF invoice
pdf_path = 'sample_invoice.pdf'
---- Grab all the text with PyPDF2 ----
raw_text = '' with open(pdf_path, 'rb') as file: reader = PyPDF2.PdfReader(file) for page in reader.pages: raw_text += page.extract_text()
Hunt for the invoice number with a regular expression
invoice_number_match = re.search(r'Invoice Number:\s*(\w+)', raw_text) if invoice_number_match: invoice_number = invoice_number_match.group(1) print(f"Found Invoice Number: {invoice_number}")
---- Pull out the table data with tabula-py ----
This grabs all tables and puts them into a list of DataFrames
tables = tabula.read_pdf(pdf_path, pages='all', multiple_tables=True)
if tables: # Let's assume the final totals are in the last table found totals_df = tables[-1] # From here, you'd write logic to find the 'Total Due' value # This part completely depends on your table's layout print("Successfully extracted tables for analysis.") This example shows a classic approach: use one tool for the loose text and another for the neatly structured tables. It offers a ton of precision, but it hinges on you knowing exactly how your documents are laid out. Once you have that, you can target data with surgical accuracy.
Automating Extraction With AI Platforms

When you're dealing with hundreds or thousands of documents, manual copy-pasting isn't just slow—it's a real liability. Even custom scripts, which seem like a good solution, often become a maintenance nightmare. A tiny layout change on a vendor invoice can break a Python script, leading to silent failures and corrupt data that can go unnoticed for weeks.
This is exactly where AI-powered platforms, known in the industry as Intelligent Document Processing (IDP), completely change the game. Instead of relying on fixed coordinates or rigid templates, these systems use machine learning to read and understand documents much like a person does. They combine Optical Character Recognition (OCR) with a deep contextual understanding, allowing them to pinpoint and pull out key information no matter where it appears on the page.
How AI Handles Document Chaos
Let's get practical. Imagine you get invoices from 50 different vendors. Each one has a completely different layout. One puts the invoice number at the top right, another sticks it at the bottom left, and a third cheekily labels it "Inv. #." A custom script would need 50 different sets of rules—one for each vendor. It's a house of cards waiting to collapse.
An IDP platform, on the other hand, is trained on millions of documents. It learns what an "invoice number" is conceptually. So, when it sees a new invoice, it uses context, keywords, and data patterns to find the right value, regardless of its position or label. You can just dump a folder of mixed-format documents into the system, and the AI takes care of the rest.
This adaptability is the secret sauce of any good AI platform. It moves beyond simple text scraping to genuine document comprehension, which is absolutely essential for any business looking to reliably automate data extraction at scale.
This isn't some niche technology anymore; it's a massive, growing market. The global intelligent document processing market was valued at USD 2.3 billion in 2024 and is projected to grow at an incredible CAGR of 24.7% through 2034. It's no surprise that a recent market analysis from GMI Insights found that 63% of Fortune 250 companies have already put IDP solutions to work.
From a Pile of PDFs to Actionable Data
Let's walk through a real-world scenario. An e-commerce company needs to process 1,000 purchase orders from various suppliers to update its inventory system. The documents are a mess—a mix of digital PDFs, grainy scanned images, and even a few Word files.
Here’s what the workflow looks like with an IDP platform:
- Upload the Mess: The entire folder of mixed-format documents gets uploaded directly to the platform. No pre-sorting or renaming is needed.
- Let the AI Work: The platform's AI engine kicks in. It uses OCR to digitize any scanned documents and then analyzes each file to find and label key fields like PO Number, Vendor Name, Line Items, Quantity, and Unit Price.
- Validate with Confidence: The system is smart enough to flag documents where it has low confidence or can't find a key piece of data. This allows a human to do a quick spot-check, ensuring 100% accuracy without reviewing every single document.
- Export and Integrate: The final, structured data is exported as a clean CSV or JSON file. It's now perfectly formatted to be imported directly into the company's inventory management software.
What used to be days of soul-crushing manual entry is now done in minutes, and with far greater accuracy. The process is repeatable, scalable, and frees up your team to focus on work that actually matters. For a deeper dive into how these systems operate, check out our complete guide on what is Intelligent Document Processing.
Choosing Your PDF Extraction Tool
Deciding on the right approach depends entirely on your specific needs—your document volume, complexity, and budget all play a role. To help you make sense of the options, here's a quick comparison of the methods we've discussed.
| Feature | Manual Copy/Paste | Open-Source Library | AI Platform (IDP) |
|---|---|---|---|
| Best For | One-off tasks, a handful of documents | Developers with coding skills, fixed layouts | High volume, varied layouts, business users |
| Scalability | Very Low | Medium (requires coding for each new type) | Very High (handles millions of documents) |
| Accuracy | Prone to human error | High for known formats, fails on variations | High, with learning capabilities |
| Setup Time | None | Hours to days of development | Minutes to hours |
| Maintenance | N/A | High (scripts break with layout changes) | Low (managed by the platform provider) |
| Cost | "Free" (but high in labor cost) | Free to use, but high in development cost | Subscription-based, low total cost of ownership |
| Example Scenario | Extracting data from 5 customer surveys | Processing 100 invoices from a single vendor | Automating 10,000 invoices from 500 vendors |
As you can see, while manual methods and open-source libraries have their place for small, predictable tasks, AI-powered IDP platforms are built for the complexity and scale of modern business operations. They offer a robust, flexible, and ultimately more cost-effective solution for anyone serious about automating document processing.
9 Proven Tips for Accurate Data Extraction
Just picking a tool is half the battle. Real success with data extraction comes from the process you build around that tool. I’ve seen it time and time again: people just throw a PDF at a parser and cross their fingers, only to end up with messy, unreliable data.
The best, most dependable workflows always have a few checks and balances built in. These are simple, practical steps that ensure the data you get out is clean and trustworthy. The following tips come from years of hands-on experience, where tiny adjustments ended up making a huge difference.
1. Start with High-Quality Inputs
You've heard the saying "garbage in, garbage out," and it's never more true than with data extraction, especially when you're working with scanned documents. The Optical Character Recognition (OCR) engine is only as good as the image it's trying to read. If your scan is blurry, crooked, or has poor contrast, the text it pulls out will be a mess of errors.
So, before you even think about extraction, spend a little time on pre-processing your files. This doesn't need to be a huge, complicated step.
- Deskewing: A simple function that automatically straightens out pages that were scanned at a slight angle.
- Noise Reduction: This gets rid of all those little stray dots and "salt and pepper" specks on a scan, leaving behind much cleaner text.
- Binarization: Converting the image to pure black and white makes the text pop, dramatically improving contrast for the OCR engine.
Most good libraries and tools have these features built-in. Taking a few moments to clean up your scans will pay off big time by boosting OCR accuracy and saving you from a headache of manual corrections down the road.
2. Implement Simple Validation Rules
Never, ever blindly trust the data you've extracted. You absolutely need a layer of automated validation to catch the most obvious mistakes. These are just simple, common-sense rules your system can use to check if the extracted data is even plausible.
For instance, date fields are a classic failure point. An OCR might read "April 1, 2024" as "Apr1l 1, Z024." A simple validation rule can check if the value is a valid date. If it fails the check, the system can flag it for a human to look at.
The point of validation isn't to find every single tiny error. It's about automatically weeding out the most glaring mistakes so your team can focus their energy on the small handful of documents that actually need a human eye.
3. Embrace a Human-in-the-Loop Workflow
Look, even the smartest AI on the planet isn't foolproof. For any business process that really matters, a human-in-the-loop (HITL) system is non-negotiable. This doesn't mean someone has to manually check every single document—that would defeat the purpose of automation.
Instead, you create a smart workflow where a person only steps in when the system flags something it's not sure about. A good AI tool will give you a confidence score for each piece of data it extracts, like 85% certain. You can then set a threshold—let's say 95%—and any field that scores below that automatically gets routed to a human for a quick double-check.
This approach gives you the best of both worlds: the raw speed of automation combined with the nuanced accuracy of human judgment.
Frequently Asked Questions About PDF Extraction

As you start digging into PDF data extraction, you'll find a few questions come up again and again. I've been there myself. Here are some straightforward answers to the most common hurdles you'll face, hopefully helping you pick the right approach for your project.
What Is the Best Way to Extract Data from a Scanned PDF?
When you're dealing with a scanned PDF, you're essentially looking at a picture of a document. There's no actual text layer to copy, which means you absolutely need a tool with Optical Character Recognition (OCR).
You could go the open-source route and write a Python script using a library like pytesseract to handle the OCR. It's a solid option for simple jobs. But in my experience, when accuracy really matters, AI-powered platforms are the way to go. They pair OCR with machine learning models that don't just read the text but also understand the document's structure, which dramatically improves accuracy, especially with tricky layouts.
Can I Extract Tables from a PDF into Excel?
Yes, this is probably one of the most popular reasons people get into PDF extraction in the first place. You might get lucky with a simple copy-paste from a digitally created PDF, but more often than not, you end up with a formatting nightmare in your spreadsheet.
For developers, a Python library like tabula-py can be a lifesaver. It’s specifically built to find tables and convert them into something you can drop into Excel. The real challenge, however, comes with scanned tables or complex ones that stretch across multiple pages. This is where an AI tool shines, as it can intelligently figure out rows and columns even when they're messy or misaligned.
The real value of AI isn't just pulling table data; it's correctly handling merged cells, multi-line rows, and inconsistent column headers that would otherwise require hours of manual cleanup in Excel.
How Do I Handle PDFs with Different Layouts and Templates?
This is the big one. This is the exact problem where most traditional methods fall apart. If you build a custom script for one specific invoice template, it's guaranteed to break the second a vendor sends you a redesigned version. Trying to create manual rules for dozens of different formats just isn't sustainable.
This is precisely why Intelligent Document Processing (IDP) platforms were created. These systems use sophisticated models trained on millions of documents, allowing them to find data based on context—like looking for "Total Amount" near the bottom of the page—instead of relying on a fixed location. It means you can funnel documents from all kinds of sources into a single, automated workflow.
- No more template building: The AI learns and adapts to new layouts without you having to configure a new template for every single variation.
- Greater resilience: Your workflow won't grind to a halt because of a minor formatting change on a supplier's invoice.
- True scalability: You can bring on new clients or process new document types without having to re-engineer your entire system.
This approach shifts your data extraction process from something brittle and high-maintenance to a system that's both flexible and reliable.
Ready to stop wasting time on manual data entry? DocParseMagic uses AI to pull structured data from any invoice, receipt, or form directly into a spreadsheet in under a minute. Define your template once and let our system do the work, no matter how messy your documents are. Try it for free and see how much time you can reclaim. Learn more at the official DocParseMagic website.