
Extract Data From Documents a Practical Guide
Let's be honest, manual data entry is a business killer. It's a massive bottleneck that slows everything down, introduces costly mistakes, and keeps your team tied up in mind-numbing work. To really extract data from documents and put it to use, businesses are now looking to AI-powered automation. It's the key to unlocking the critical information trapped in your invoices, contracts, and forms, turning a major pain point into a real competitive advantage.
Why Liberating Your Trapped Data Matters
For so many companies, crucial information is essentially locked away in digital filing cabinets—stuck inside PDFs, scanned images, and Word documents. This isn't just a messy organizational problem; it’s a huge operational drag that directly hits your bottom line and your ability to move quickly. Every time someone on your team has to manually find and re-type information, you're building in delays and opening the door to human error.
The costs of sticking with old-school document handling are pretty shocking. Globally, companies lose an estimated $1 trillion every single year because of inefficient document workflows, a problem that almost always comes back to manual data entry. You can find more of these eye-opening document processing statistics on sensetask.com. Making the switch to automation isn't just about saving a few hours here and there; it’s about reclaiming lost revenue and freeing up valuable resources.
The Real-World Impact of Automation
When you move from manual to automated data extraction, the effects are immediate and measurable. Think about an accounting clerk who burns hours every week just keying in invoice details. With an automated system, that same person can push hundreds of invoices through the system in minutes. Suddenly, they're free to focus on actual financial analysis and managing vendor relationships—work that adds real value. It’s a complete shift toward a more strategic, high-impact workforce.
This transformation is pretty clear when you see it in action:
- Lightning-Fast Processing: Tasks that used to take days can now be wrapped up in minutes. For example, a customer onboarding process that was held up by manual form reviews can become almost instantaneous.
- A Massive Drop in Errors: Automation gets rid of typos and transposition mistakes. For financial documents like receipts, getting this right is non-negotiable for compliance. In fact, we have a whole guide on this topic you can find here: https://docparsemagic.com/blog/how-to-organize-receipts-for-taxes
- Happier, More Engaged Employees: Nobody enjoys tedious, repetitive work. When you take that off your team's plate, they can dive into more meaningful projects that challenge them, which is a huge boost for job satisfaction and helps prevent burnout.
The table below gives a quick snapshot of just how different these two approaches are.
Manual vs Automated Data Extraction
| Metric | Manual Processing | Automated Extraction |
|---|---|---|
| Speed | Slow, often taking hours or days per batch | Near-instantaneous, processing thousands of documents in minutes |
| Accuracy | Prone to human error (typos, misinterpretation) | Over 99% accuracy, with built-in validation rules |
| Cost | High labor costs, plus the cost of fixing errors | Low per-document cost, frees up employee time for higher-value work |
| Scalability | Difficult to scale; requires hiring more people | Easily scales to handle fluctuating volumes without extra staff |
| Employee Impact | Tedious, repetitive work leading to low morale | Empowers employees to focus on strategic tasks, boosting job satisfaction |
The difference is night and day. Automation doesn't just do the same work faster; it fundamentally changes what your team is capable of accomplishing.
The real goal here isn't just to pull data out of a document; it’s to build a smarter, more resilient foundation for your entire operation. By automating, you create a smooth, reliable flow of information that leads to better decisions, ensures you stay compliant, and lets your business grow without getting buried under a mountain of administrative work. This is how you carve out a genuine competitive edge.
Mapping Your Documents and Data Needs
Before you even think about looking at software, the most important thing you can do is create a solid game plan. I’ve seen it time and again: people get excited about a new tool, jump right in, and then wonder why it’s not working. It’s like buying a car without knowing if you need to haul lumber or just get to work in the city.
A quick audit of your documents is the secret to getting this right and avoiding a lot of headaches down the road.
First, let's sort your documents into a few key categories. This simple act of organization will tell you what kind of technology you actually need to extract data from documents without a ton of manual cleanup. Most of the paperwork floating around a business falls into one of three buckets.
The Three Main Document Types
Thinking about your documents this way is crucial because it helps you match the problem to the right tool. For example, a simple, old-school extractor that relies on templates might work perfectly for structured forms, but it will fall flat on its face when it sees a complex contract. It’s all about knowing what you’re dealing with.
-
Structured Documents: These are the easy ones. Think of standardized forms, surveys, or simple tax documents where every field is in the exact same spot, every single time. Predictable and clean.
-
Semi-Structured Documents: This is where most business documents live. Invoices, purchase orders, and receipts are classic examples. They all contain the same core information (like vendor, total, date), but the layout can be completely different from one to the next.
-
Unstructured Documents: These have no predictable format at all. We're talking about legal contracts, emails, and detailed reports. The gold is buried in paragraphs of text, making it the toughest data to get out reliably.
Here's a reality check: for most businesses, over 80% of their data is unstructured or semi-structured. This is exactly why modern AI-powered tools have become so important—they're built to handle the messy, real-world variability that trips up older systems.
Pinpointing the Exact Data You Need
Once you know what you're working with, the next question is: what information do you actually need to pull from these documents? Being vague here is a recipe for disaster, leading to messy, unusable data. You have to get specific.
Let's take a simple invoice as an example. You could just say "I need the total," but that's not enough. A proper data map for your accounting team would look more like this:
- Vendor Name: The full legal name of the company.
- Invoice Number: The unique ID for that specific bill.
- Invoice Date: The date the invoice was issued.
- Due Date: The payment deadline.
- Line Items: A detailed breakdown of each product or service, including its quantity, description, and price.
- Subtotal: The total before taxes and fees.
- Tax Amount: The exact amount of sales tax charged.
- Grand Total: The final, all-in amount due.
This level of detail is non-negotiable. It’s what ensures the data you extract is complete and ready to be fed directly into your accounting software or ERP system. Taking a little time to map out these needs upfront is the single best thing you can do to make sure your project is a success from day one.
Finding the Right Tool for the Job
Okay, so you've mapped out all the different documents flying around your business. Now comes the real decision: how are you actually going to get the data out of them? This is a crucial step, and picking the wrong approach can lead to a lot of headaches and wasted time down the line. The best tool really depends on the documents you’re working with—are they perfectly structured, a bit of a mess, or completely free-form?
The Old-School Way: Template-Based Extraction
Many people start with traditional, template-based systems. Think of these as the rigid rule-followers of the data extraction world. If you're processing a specific form that looks exactly the same every single time, a template can be a solid choice. You basically draw boxes on the document and tell the software, "the invoice number is always here."
The problem? The real world is messy. As soon as a supplier tweaks their invoice layout even slightly—maybe they move the date to the other side of the page—the template breaks. This brittleness is their fatal flaw, making them a poor fit for any business dealing with documents from multiple sources.
The Ground Floor: Optical Character Recognition (OCR)
Beneath almost any modern extraction method, you'll find Optical Character Recognition (OCR). It’s the foundational tech that turns pictures of text into actual, machine-readable text. It scans a PDF or an image, recognizes the characters, and spits them out. Simple as that.
But here’s the catch: OCR reads text, it doesn't understand it.
An OCR tool can see the characters "Invoice #12345," but it has no clue that "12345" is the specific piece of data you care about. It's a fantastic first step, but it's just a first step. If you only handle one or two consistent forms, a basic OCR tool might get you by. But for anything more complex, you'll hit a wall fast.
The real game-changer isn't just reading the words; it's understanding what they mean in context. A truly smart system knows that "INV-987" and "Bill No. 987" are both invoice numbers, even if they're in different spots on the page. And that's where AI comes in.
The Modern Approach: Intelligent Document Processing (IDP)
This brings us to the most flexible and powerful option out there: Intelligent Document Processing (IDP). Platforms that use IDP start with OCR to read the text, but then they bring in the heavy hitters: artificial intelligence, machine learning (ML), and Natural Language Processing (NLP). This powerful combination allows the software to move beyond just reading and start comprehending—much like a person would.
An IDP solution doesn't rely on fragile templates. Instead, it learns to spot key information by looking for contextual clues. It figures out that the number next to "Total Due" is the one you want, no matter where it appears on the invoice. This kind of adaptability is a lifesaver when you’re handling semi-structured documents, like invoices from hundreds of different vendors. You can get a much deeper look into what is intelligent document processing and see exactly how it all works.
This AI-powered approach isn't just a "nice-to-have" anymore. With projections showing that global data will reach an incredible 175 zettabytes by 2025, the need for smarter extraction is becoming urgent. Modern AI and ML models are already hitting accuracy rates between 98% to 99%, making them essential for any company that relies on its data. For a growing business, trying to scale with rigid templates just isn't sustainable. A flexible IDP platform is no longer a luxury—it's a strategic necessity.
Putting Your AI Data Extraction Solution into Practice
Alright, let's move from theory to action. This is where we roll up our sleeves and walk through the actual setup of an intelligent tool to extract data from documents. We'll skip the generic talk and use a real-world scenario that’s a headache for many businesses: processing a messy pile of purchase orders from all your different suppliers.
The great thing about modern AI tools is that you don't need a computer science degree to get started. The process feels surprisingly intuitive. The core idea is simple: you show the AI what you're looking for, and it learns to find that information on its own, even on documents it's never seen before.
This visual gives you a good sense of the evolution from rigid, old-school methods to the flexible AI approach we're using today.
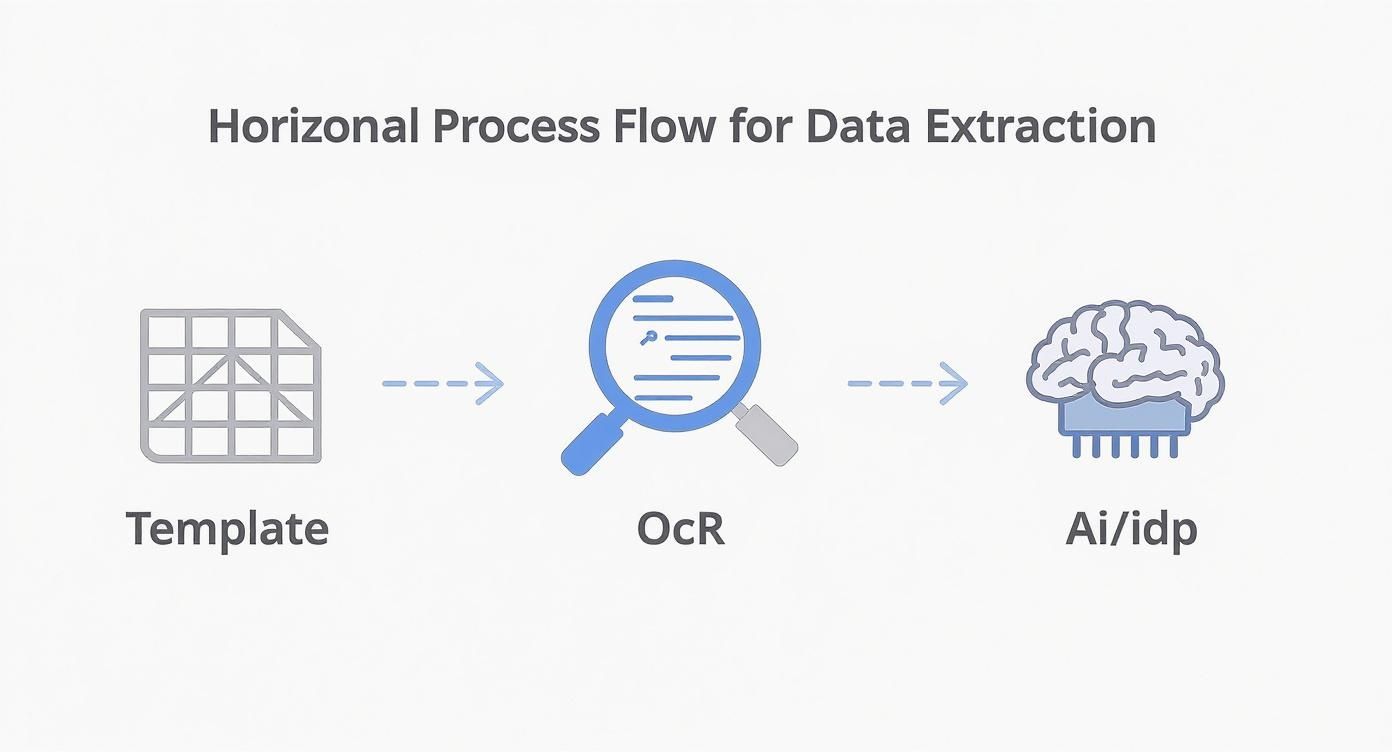
As you can see, we’ve moved past simple templates and basic OCR. We’re now in the realm of intelligent, context-aware AI, which is what makes this whole thing so powerful.
Training Your First AI Model
To kick things off, you'll need a small but representative sample of your documents. For our purchase order example, this means grabbing five to ten different POs from various vendors. The trick is to pick documents that show the variety your system will have to deal with—different layouts, different fonts, you name it.
Once you’ve uploaded them, you’ll use the platform’s interface to "label" or "annotate" the key data fields. It’s a lot less technical than it sounds. You literally just draw a box around the 'PO Number' on a couple of examples and tag it as such.
You'll do the same for all the other important bits of information:
- PO Number: The unique code for that specific order.
- Vendor Name: Who you're buying from.
- Shipping Address: Where the goods are headed.
- Total Amount: The bottom-line cost.
After you've labeled a handful of samples, you tell the system to start training. The AI gets to work, analyzing your examples and learning the contextual clues—things like the words "PO #," "Vendor," or "Ship To"—so it can spot these fields on brand-new documents. This whole training step is surprisingly fast, often taking just a few minutes.
Testing and Fine-Tuning for Accuracy
With your first model trained, it's time to put it to the test. The next move is to process a larger, more varied batch of documents to see how well it performs. This is your chance to validate the accuracy and spot any areas that might need a little tweaking.
Most modern platforms make this part easy. You’ll typically see the extracted data presented right next to the original document, often with a confidence score for each field. A 99% confidence score on a vendor name is a good sign, but if you see a 65% on the total amount, that's your cue to take a quick look.
Reviewing these exceptions is a critical part of the process. If you find a field the AI got wrong, you just correct it. Every correction you make is direct feedback that makes the model smarter and more accurate for the next run. This "human-in-the-loop" validation is a powerful feature that continuously sharpens performance over time.
The goal isn't just to pull data out of a document. It's to build a reliable, self-improving engine. Each correction is an investment that pays off with higher accuracy and less manual work down the line, ultimately leading to a truly automated workflow.
Putting Your Clean Data to Work
Once you're happy with the model's accuracy, you're ready to flip the switch. The final piece of the puzzle is getting that clean, structured data out of the extraction tool and into the systems where it can actually drive your business forward.
Most platforms give you a few different ways to do this, making it easy to plug into your existing operations. The most common export options include:
- Direct Download: The simplest route is often just to download the results as a CSV or Excel file. From there, you can easily upload it into your accounting software or ERP.
- API Integration: For a completely hands-off process, you can use an API to pipe the extracted data directly into other applications like QuickBooks, Xero, or a custom-built database.
By following this practical path—uploading samples, labeling key fields, testing, and refining—you can build an incredibly effective system to extract data from documents without needing a team of data scientists. The end result is clean, structured data, ready to power smarter, faster business decisions.
Making Your Extracted Data Work for You
Getting clean, structured data out of your documents is a huge win, but honestly, it’s only half the battle. The real value unlocks when that data starts working for you automatically, without anyone needing to lift a finger. This is the point where you go from having a cool extraction tool to genuinely overhauling your business processes.
The whole idea is to build a seamless, hands-free bridge between the information locked in your documents and the software you rely on every day. Once you extract data from documents, it shouldn't just sit in a spreadsheet waiting for someone to copy and paste it. That data needs to flow directly where it’s needed most.
This shift toward automation is why we're seeing such massive investment in this space. The global market for Intelligent Document Processing (IDP) is expected to explode, reaching about USD 17.8 billion by 2032. That’s driven by a massive 28.9% compound annual growth rate. This isn't just a fleeting trend; it’s a fundamental change in how companies get things done, with 63% of Fortune 250 businesses already using this kind of technology. You can dig into more of these stats on the rise of IDP adoption at scoop.market.us.
Getting Data into Your Core Systems
So, how do you actually make this connection? Most modern data extraction platforms give you a few different ways to plug into your existing software stack. You can go from simple file exports to powerful, direct connections that run in the background.
Here are the most common ways I see people do it:
- CSV or Excel Exports: This is the most straightforward method. You simply export the structured data into a spreadsheet and then upload it directly into your accounting software, ERP, or CRM. It’s perfect for batch processing, like tackling all of yesterday's invoices in one go.
- API Integrations: For true, set-it-and-forget-it automation, this is the gold standard. An API (Application Programming Interface) lets your extraction tool "talk" directly to your other software, sending data over in real-time without anyone having to click a button.
- Connectors like Zapier or Make: If you're not a developer, don't worry. Services like Zapier act as a middleman. You can create simple "if this, then that" rules. A classic example is: "When a new invoice is processed, automatically create a new bill in QuickBooks."
The main goal is to get rid of the manual handoff. Every single time a person has to touch the data after it's been extracted, you're introducing a potential point of failure and adding delays. True automation builds a direct pipeline from the document right into your system.
A Look at Automation in the Real World
Let's walk through a practical example. Imagine your accounts payable team is stuck doing "three-way matching"—that crucial but tedious process to prevent fraud and overpayment. It involves manually checking that the details on an invoice line up with the purchase order and the delivery receipt.
Doing this by hand is a nightmare of shuffling papers and squinting at spreadsheets. With an integrated workflow, the entire process looks completely different.
- Automated Extraction: The system grabs all the key data points from the three documents—invoice number, PO number, line items, and quantities.
- System Cross-Verification: That data instantly flows into your accounting system, which automatically checks if the numbers on all three documents align.
- Flagging for Review: If everything matches up, the invoice is automatically approved for payment. If there’s a discrepancy, it gets flagged and sent to a human for a quick review.
This one workflow alone can save a team dozens of hours every single week. It’s how you turn a simple data extraction tool into a powerful business asset. If you want to dive into more ideas, we've put together a guide on complete document workflow automation that you might find useful.
Answering Your Top Questions About Document Data Extraction
When you first start looking into pulling data from documents with AI, the same handful of questions always seem to surface. It's completely normal. Let's walk through them, because getting good answers is the first step to feeling confident about your project.
Just How Accurate Is This AI Stuff?
This is probably the most important question, and the answer is surprisingly good. For most standard documents, a modern Intelligent Document Processing (IDP) solution can hit 98-99% accuracy right out of the box.
Of course, the quality of your documents matters. A crisp, clean PDF will always give you better results than a grainy photo of a crumpled receipt.
But the real magic is the "human-in-the-loop" feature that good platforms offer. It's a safety net. The AI flags any field it's not sure about, letting a real person give it a quick once-over. This not only gets you to 100% accuracy but also trains the AI, making it smarter for the next time.
It's crucial to remember that AI isn't just reading words; it's understanding them. It can tell the difference between an 'invoice number' and a 'PO number' by looking at the surrounding text and layout. That contextual awareness is what makes it so powerful.
Is This Just Fancy OCR?
I hear this one all the time. It's a fair question, but there’s a big difference. Let's break it down simply:
-
Optical Character Recognition (OCR) is the foundational tech. It’s been around for decades. Its one and only job is to look at an image and turn the shapes it sees into text characters. It can read, but it has zero comprehension.
-
Intelligent Document Processing (IDP) is the whole package. It starts with OCR to get the raw text, then layers on AI, machine learning, and Natural Language Processing (NLP) to figure out what that text actually means. An IDP platform doesn't just see "123-ABC"; it knows it's the invoice number.
Think of OCR as the eyes and IDP as the brain. You need both to get the job done right.
How Much of a Tech Whiz Do I Need to Be?
Honestly, probably less than you think. The game has changed. Most of the best cloud-based tools are built with a no-code, user-friendly approach.
If you can upload a few sample invoices and use your mouse to draw a box around the fields you want to extract, you have all the technical skill you need to get started. It's really that straightforward for the initial setup.
Now, if you want to build a completely hands-off workflow where the extracted data automatically zips over to your accounting software or ERP system, you'll likely need a bit of help. That usually involves using an API, which might be a quick job for a developer or someone on your IT team.
Ready to stop wasting time on manual data entry? DocParseMagic uses AI to pull the exact information you need from any document and delivers it as a clean spreadsheet in under a minute. Try DocParseMagic for free and see your results instantly.